
基于生成对抗网络的数据增强方法在语义分割中的应用
简介:
生成对抗网络(GAN)的图片生成能力已经到了令人叹为观止的地步。比如:


以及这些:

这些惟妙惟肖的人脸图片都不是真实的照片,而是由英伟达公司的StyleGAN自动生成的。
除了生成可以以假乱真的人脸以外,我们与北航智能计算与机器学习实验室(http://dsd.future-lab.cn) 合作提出了GAN的另一种用途——用于语义分割任务的数据增强。大家都知道,数据集的标注一直都是一项耗时耗力的工作,特别是对于语义分割任务中像素级别的高精度数据而言。另一方面,数据集中普遍存在着类别不平衡的问题:一些类别总是频繁的出现,而另一些类别在数据集中的占比却少的可怜。利用GAN强大的图片生成能力,提出了一种用GAN来生成数据的策略,可以较好地解决数据标注困难以及数据集类别分布不平衡的问题。
该方法利用GAN这一类的生成模型作为数据生成器,将语义标签图转换为增补数据集。这样我们通过对语义标签图进行操作,就可以实现对特定类别的增加。并且在GAN的帮助下,可以以极高的效率生成新的数据。实验结果表明,借助该数据增强方法,可以将语义分割网络的分割准确率提升2.1%左右。
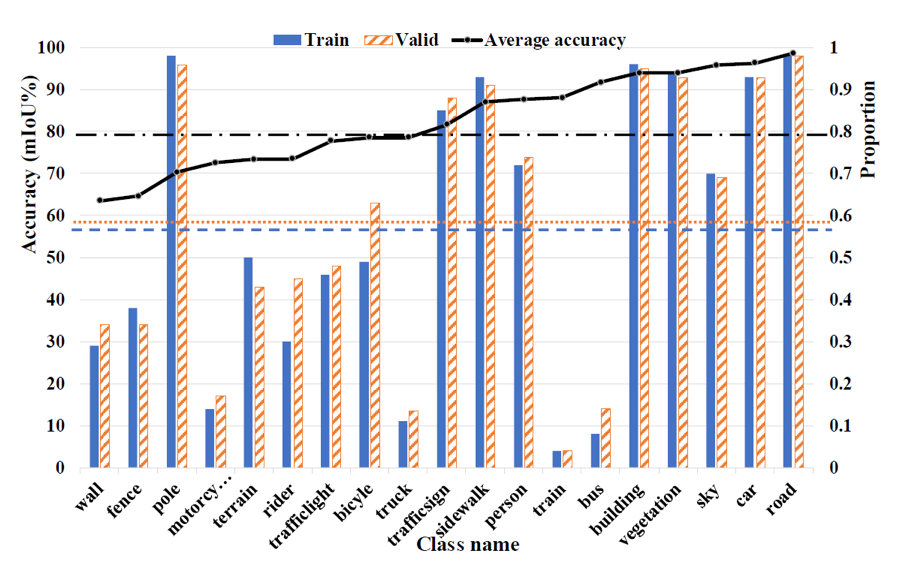
类别分布对语义分割的影响:
现有的数据集大多都存在着类别分布不均的问题。以Cityscapes数据集为例,车、道路等类别的出现频率非常高,几乎每张图片里都有;而墙、篱笆等类别则很少出现。该团队对类别分布和语义分割准确率之间的关系进行了分析,二者之间呈很高的相关性,如图1所示。某一标签类分割的准确率与其在数据集中的占比成正相关。
方法介绍:
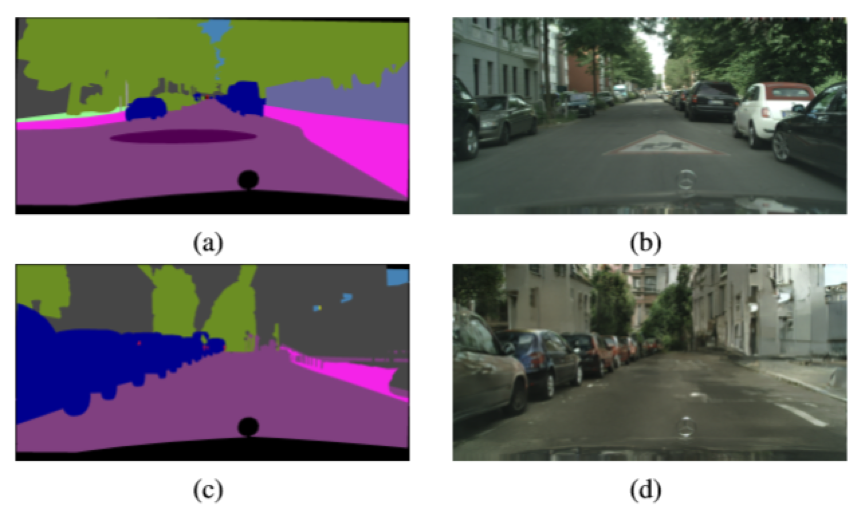
原数据集中的数据包括原始照片(图2b)和对应的类别标签(图2a)。该方法的核心思想是利用GAN能够生成以假乱真的图片的特性,将标签图(图2c)转换为真实图(图2d)。
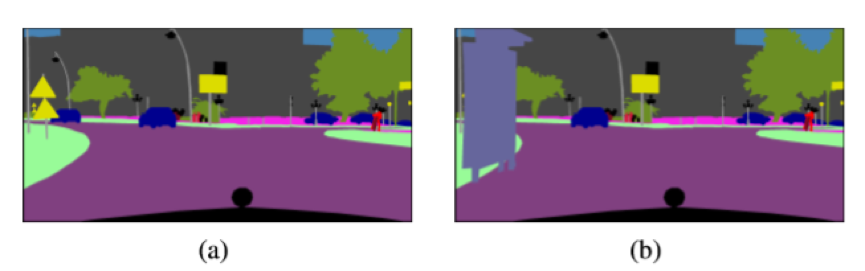
这样以来,便可以通过对标签图进行操作,生成我们需要的补充数据,从而改善原数据集类别分布不均的问题。例如,原数据集中墙这一类较少,我们便可以在标签图中增加更多墙的标签(如图3a中的浅黄色区域变成了图3b中的浅蓝色区域),然后用这种新生成的标签图作为GAN的输入,从而得到包含更多墙的“真实”图片。
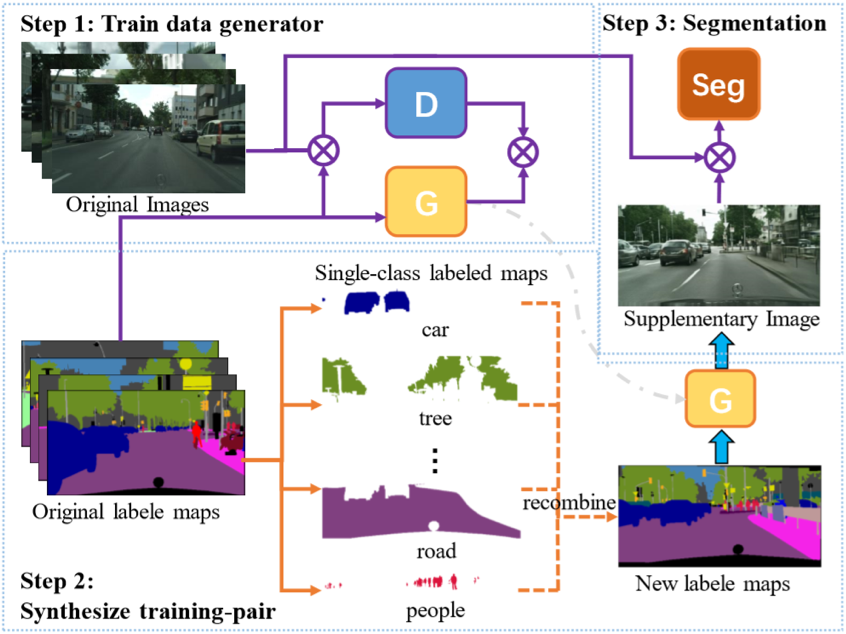
该方法的细节实现如图4所示。主要分为三个步骤:1. 训练一个能将语义标签图转换为“真实”照片的GAN模型。2. 对语义标签图进行分割与重组。3. 将重组的标签图转换为“真实”照片图像,并和原数据集混合,对分割网络进行训练。
原始数据集中的照片(图2b)、语义标签图(图2a)、新的语义标签(图2c)和经过生成器生成的图像(图2d)如图2所示。
实验结果:
- 有效性实验:
该团队设计了三种数据增强的方式:1. 只增加一个类别的数量(墙)。2. 增加多个类别的数量。3. 完全重新组合数据集。三种数据增强的结果如图5所示。可以看出,它们都在一定程度上提高了原本分割准确率较低的类的分割准确率。

- 对比实验
与传统的旋转和缩放增强方式以及如图6所示的风格迁移增强方式进行对比实验。

实验结果表明,该方法均优于传统的数据增强方法和风格迁移方法,使得分割网络的准确率提高了2.1%。
总结:
该数据增强方法能够利用生成对抗网络(GAN),高效地生成大量新的数据集,改善原数据集中类别分布不均、场景不够丰富等问题,从而有效地提高语义分割网络的准确性。该工作已经被ICASSP 2019接收,Arxiv链接如下:
http://arxiv.org/abs/1811.00174

